
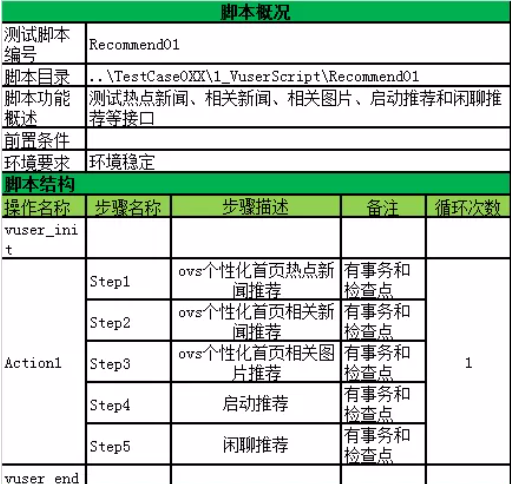
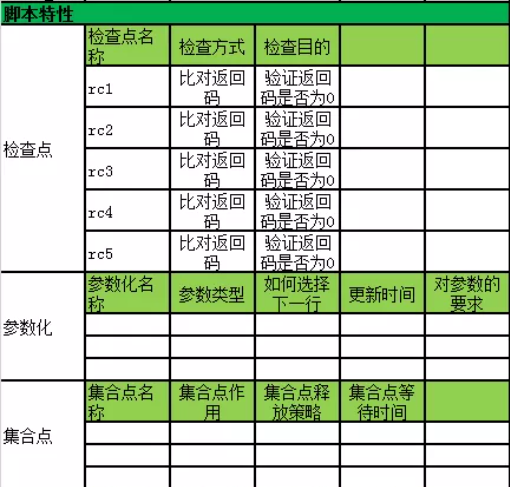
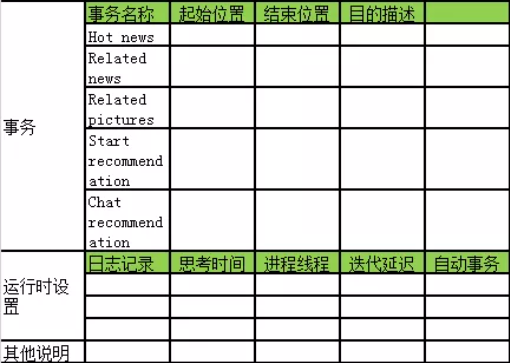
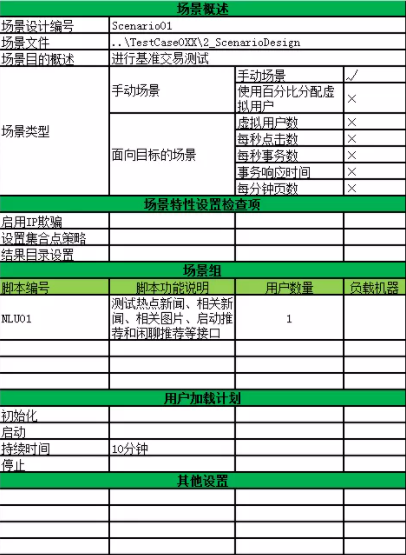
性能测试工具选择
1. 数据建模工具
DataFactory是一种强大的数据产生器,它允许开发人员和QA很容易产生百万行有意义的正确的测试数据库,该工具支持DB2、Oracle
、 Sybase、SQL Server数据库,支持ODBC连接方式,无法直接使用MySQL
数据库,可间接支持。
2. 脚本开发工具
(1) 若考虑脚本运行效率,则可考虑底开发语言C或支持异步通信的语言JS,我们可以分别选择:Loadrunner 或 Node.js
的IDE环境进行开发。
(2) 若考虑脚本开发效率,则可考虑代码复用性,可以选择面向对象语言C#或Java,为此我们可以分别选择:VS2008及以上版本 +对应LR.NET
控件 或者 Eclipse4.0及以上版本 + JDK1.7及以上版本。
3. 压力模拟工具
(1) 若为Java类接口且单机并发数控制在500内,则可选择Jmeter或者 Loadrunner。
(2) 若为WebService类接口且单机并发数控制在500内,则可选择SoapUI或者Loadrunner。
(3) 若单机并发数超过500且控制在5000内,则可选择Loadrunner。
(4) 若单机并发数超过5000,则建议采用负载集群,即采用“中控(Control Center)+ 多机部署(LoadGenerator)”方案。
4. 性能监控工具
4.1 监控工具
无论Windows或Linux
平台,一般存在的是一个或一组进程实例,我们可以选择Loadrunner 或 Nmon 来监控。有时为了获取被测应用的一些特性指标,可以选择被测组件自带的性能工具集或监控系统。常见应用服务器监控工具推荐如下:

4.2 监控平台
监控机器主要对被测集群服务器的服务或资源使用情况进行监控,比如各种开源的监控工具,MRTG:流量监控;CACTI:流量预警,性能报告Smokeping:IDC 质量监控;综合监控:Nagios、Zenoss、Ganglia 、Zabbix、Sitescope、Hyperic HQ 等,如下所示:

4.3 第三方监控云服务(APM)
APM提供端到端应用性能管理软件及应用性能监控软件解决方案,包含移动,浏览器,应用,基础设施,网络,数据库性能管理等,支持Java、.NET、PHP
、Ruby、Python
、Node.js、iOS
、Android
、HTML5
等应用性能监控管理,主流云服务包括听云、OneAPM等,如下所示:

性能测试结果分析
1. 指标分析
性能测试的指标可分为产品指标和资源指标两类。对测试人员而言,性能测试的需求来自于用户、开发、运维的三方面。用户和开发关注的是与业务需求相关的产品指标,运维人员关注的是与硬件消耗相关的资源指标。
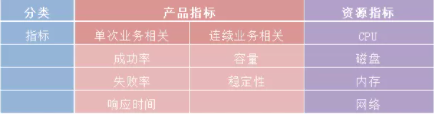
(1) 从用户角度关注的指标
用户关注的是单次业务相关的体验效果,譬如一次操作的响应快慢、一次请求是否成功、一次连接是否失败等,反映单次业务相关的指标包括:
a.成功率b.失败率c.响应时间
(2) 从开发角度关注的指标
开发人员更关注的是系统层面的指标。
a.容量:系统能够承载的最大用户访问量是多少?系统最大的业务处理量是多少?
b.稳定性:系统是否支持7*24小时(一周)的业务访问。
(3) 从运维角度关注的指标
运维人员更关注的是硬件资源的消耗情况。

以上说明了测试人员在选择指标时需站在用户角度去思考,另外为了后续能够更好地分析问题,更需掌握与被测组件特性或运行原理相关的性能指标。
举例来说,通常接口系统均会直接或间接地访问数据库层介质(如Mysql、Oracle、SQLServer等),此时我们需考虑由接口系统产生压力下存储介质的性能情况,通常我们会选择分析指标如下:
(1) 连接数(Connections)
(2) 每秒查询数/每秒事务数(QPS/TPS)
(3) 每秒磁盘IO数(IOPS)
(4) 缓存命中率(Buffer Hits)
(5) 每秒发生的死锁数(Dead Locks/sec)
(6) 每秒读/写字节数(Read/Write Bytes/sec)
2. 建模分析
2.1 理发店模型

图中展示的是1个标准的软件性能模型。在图中有三条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。
在这张图中我们可以看到,最开始,随着并发用户数的增长,资源占用率和吞吐量会相应的增长,但是响应时间的变化不大;不过当并发用户数增长到一定程度后,资源占用达到饱和,吞吐量增长明显放缓甚至停止增长,而响应时间却进一步延长。如果并发用户数继续增长,你会发现软硬件资源占用继续维持在饱和状态,但是吞吐量开始下降,响应时间明显的超出了用户可接受的范围,并且最终导致用户放弃了这次请求甚至离开。
根据这种性能表现,图中划分了三个区域,分别是Light Load(较轻的压力)、Heavy Load(较重的压力)和Buckle Zone(用户无法忍受并放弃请求)。在Light Load和Heavy Load 两个区域交界处的并发用户数,我们称为“最佳并发用户数(The Optimum Number of Concurrent Users)”,而Heavy Load和Buckle Zone两个区域交界处的并发用户数则称为“最大并发用户数(The Maximum Number of Concurrent Users)”。
当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃;而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。所以我们应该保证最佳并发用户数要大于系统的平均负载。
2.2 压力变化模型
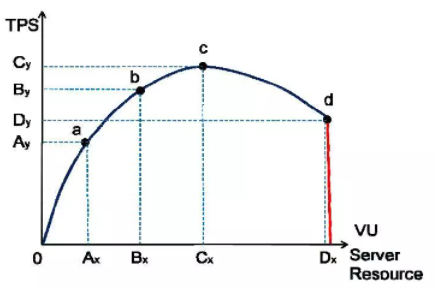
随着单位时间流量的不断增长,被测系统的压力不断增大,服务器资源会不断被消耗,TPS 值会因为这些因素而发生变化,而且符合一定的规律。
图中:
a 点:性能期望值
b 点:高于期望,系统资源处于临界点
c 点:高于期望,拐点
d 点:超过负载,系统崩溃
2.3 容量计算模型
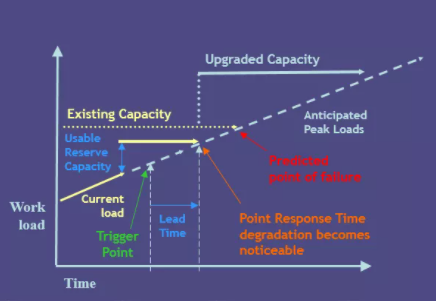
以一网站性能测试为案例:
1. 通过分析运营数据,可以知道当前系统每小时处理的PV数
2. 通过负载测试,可以知道系统每小时最大处理的PV数
即整理得
系统每小时PV处理剩余量 = 系统每小时最大处理的PV数 — 系统每小时处理的PV数
假设该网站用户负载基本呈线性增长,现有系统用户数为70万,根据运营推广计划,1年内该网站发展用户将达到1000万,即增长了14倍。即整理得:
系统每小时PV处理增加量 = 当前系统每小时处理的PV数 * 14 — 当前系统每小时处理的PV数
每天系统负载增加率 = 100% / 365 = 2.74 % (备注:此处将未来系统用户数达到1000万的负载定义为 100% )
系统每天PV处理增加量 = 系统每小时PV处理增加量 * 每天系统负载增加率 * 24
所以,我们可以知道在正常负载条件下:
系统可支持正常运行天数 = 系统每小时PV处理剩余量 * 24 / 系统每天PV处理增加量
假设该网站后续部署升级天数已知,这样我们可以知道提前升级的天数:
系统可支持正常运行天数 — 部署升级天数。
性能测试通过标准
1. 所有计划的测试已经完成。
2. 所有计划收集的性能数据已经获得。
3. 所有性能瓶颈得到改善并达到设计要求。



-
 芦花荡读后感 场面描写片段 西厢记读后感 优秀员工获奖感言简短 领导新年致辞 一句让对方暖心感觉甜蜜的话 cf网名 四级作文模板万能句型 早晨的句子发朋友圈 教研组活动记录 英语作文 时光不老我们不散形容友情 漫画老师五年级作文 高一班主任工作计划 小班观察记录 离开一座城市发朋友圈 自我总结鉴定 整蛊短信 螃蟹不能和什么一起吃 军训新闻稿 公关是什么 平凡而伟大的唯美句子 哈利波特读后感 个人工作心得 意境唯美的段落摘抄 民间故事作文 一句话泪崩的父亲文案 保密管理制度 最美铁路人观后感 博尔赫斯语录(0) 回复 (0)
芦花荡读后感 场面描写片段 西厢记读后感 优秀员工获奖感言简短 领导新年致辞 一句让对方暖心感觉甜蜜的话 cf网名 四级作文模板万能句型 早晨的句子发朋友圈 教研组活动记录 英语作文 时光不老我们不散形容友情 漫画老师五年级作文 高一班主任工作计划 小班观察记录 离开一座城市发朋友圈 自我总结鉴定 整蛊短信 螃蟹不能和什么一起吃 军训新闻稿 公关是什么 平凡而伟大的唯美句子 哈利波特读后感 个人工作心得 意境唯美的段落摘抄 民间故事作文 一句话泪崩的父亲文案 保密管理制度 最美铁路人观后感 博尔赫斯语录(0) 回复 (0) -
讨债公司/蓝月传奇辅助/蓝月辅助(0) 回复 (0)


