
“只要你不敢以MySQL专家自诩,又岂敢错过这本神书?”“一言以蔽之,写得好,编排得好,需要参考时容易到爆!”“我可是从头到尾看了一遍上一版,可还是毫不犹豫拿起了这本书,而且看完后一点都不后悔……”

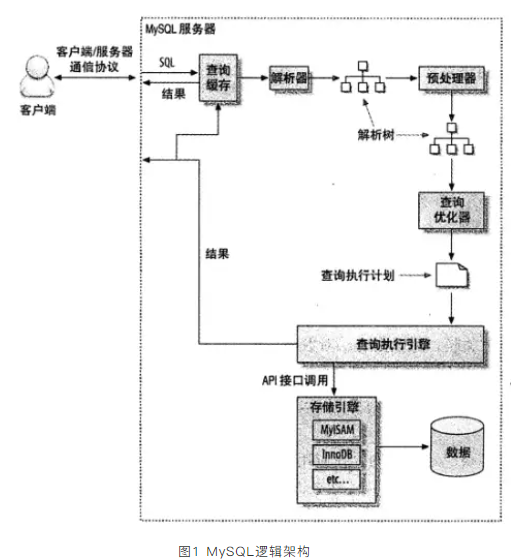
MySQL架构
Server层:包括客户端连接器、查询缓存、解析/预处理器、优化器、执行器等,以及MySQL内置函数和所有跨引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层:负责数据的存储和读取,为插件式架构,支持innoDB、MyISAM、Memory等多个存储引擎,InnoDB为默认存储引擎。
表存储
-
表结构定义:在MySQL8.0之前,只能存在于.frm 后缀文件中(MySQL Server层和InnoDB中均存在);之后允许将其放在系统数据表中。 -
表数据:包括数据段(主键索引)和索引段(二级索引),由innodb_file_per_table参数控制存储位置, 自5.6.6开始,默认配置为ON。 -
OFF表示,存放在系统共享表空间 -
ON表示,单独存放在一个.ibd文件中
-
而在共享表空间中存储,即使将表删除,空间也是不会回收的。因为InnoDB 中数据以B+树结构组织,删除其中一部分记录,只是将其相应的位置标记为删除可复用(由于索引排序,记录只能被相应的数据所复用);而当数据页上所有记录都被删除时,意味着数据页可以复用到任意位置。
-
recreate table: alter table t engine = InnoDB,可以实现在线重建表,短暂持有MDL写锁,之后持有MDL读锁。使用一个rowlog存储重建表期间表数据的修改记录,不会阻塞其他事务的增删改。 -
analyze table t 对表的索引信息做重新统计,没有修改数据,加MDL读锁。 -
optimize table t 等于recreate+analyze。
日志
MySQL日志:
-
binlog:在对数据进行增删改之后,都将会记录一条binlog,可用于数据归档和备份,存在两种格式的binlog_format: -
statement记录的是SQL语句,最后会有COMMIT。 -
row记录的实际操作的数据记录,最后会有一个XID event。
-
-
redolog:在对数据进行增删改之后,都将会记录一条redolog。其为物理日志,记录的是在某个数据页上做了什么修改,可用于崩溃后恢复事务数据和减少更新数据时的磁盘IO访问。innodb_flush_log_at_trx_commit这个参数设置成1的时候,表示每次事务的redo log都直接持久化到磁盘。 -
undolog:在事务中对数据每进行一次修改便会记录一次undolog,用于将最新数据恢复到之前事务版本。在长事务中可能占用大量存储空间。在系统判定undo-log无用时,会将其删除,即在没有比回滚日志更早的Read View时。
索引
-
聚簇索引(主键)
聚簇索引的叶子结点存的是整行数据。 -
二级索引
二级索引分为唯一和普通索引,叶子结点中存的是主键的值,如果需要获取整行数据,需要使用主键值再去聚簇索引中回表查询。
创建高性能索引
InnoDB 事务
如何启动/回滚事务:
-
手动使用 BEGIN, ROLLBACK, COMMIT来实现;BEGIN 开始一个事务,ROLLBACK 事务回滚,COMMIT 事务提交 -
直接用 SET AUTOCOMMIT = 0/1 来改变 MySQL 的自动提交模式: -
手动开启手动提交:当用户执行start transaction命令时(事务初始化),一个事务开启,当执行commit命令时事务提交,若不执行commit命令,系统则默认事务回滚。 -
自动开启自动提交:如果用户在当前情况下未执行start transaction命令而对数据库进行了操作,系统则默认用户对数据库的每一个操作为一个孤立的事务,也就是说用户每进行一次操作系都会即时提交或者即时回滚。
-
若参数autocommit=0(禁止自动提交),事务则在用户本次对数据进行操作时自动开启,在用户执行commit命令时提交,用户本次对数据库开始进行操作到用户执行commit命令之间的一系列操作为一个完整的事务周期。若不执行commit命令,系统则默认事务回滚。总而言之,当前情况下事务的状态是自动开启手动提交。 -
若参数autocommit=1(系统默认值,开启自动提交),事务的开启与提交又分为两种状态:
-
事务提交:
-
第一阶段是在更新完数据后,记录redo-log,这时redolog状态为prepare -
第二阶段是在记完redo-log之后,记录bin-log,将redolog状态置为commit
事务恢复
-
如果redo log里面的事务是完整的,也就是有prepare、commit标识,则直接提交; -
如果redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否是存在并且完整的,如果是,则提交事务;否则,回滚事务。
实现事务隔离
-
在可重复读级别下,整个事务存在期间都使用同一个视图,只会获取小于等于当前事务Id版本数据,如果数据被更新了,就通过undolog计算得到相应版本的数据,解决了不可重复读问题。 -
在读提交级别下,视图在每条SQL执行期间创建,只获取已提交的最新事务版本数据,所以每条SQL看到的数据可能都是不一致的,存在不可重复读问题。
事务问题
-
在可重复读级别下,每条SQL使用到的锁需要等到事务提交或回滚之后才释放,存在长事务时,可能会占用的更多的资源,如锁、undolog等,所以应避免长事务并且将资源占用较多的SQL放在事务后程进行。 -
在读提交级别下,每条SQL使用到的锁在SQL执行完成后便会释放,在多事务并行时,如果binlog_format=statement时可能造成数据和binlog的不一致,所以应将其设置为row。
InnoDB 行锁、间隙锁、临键锁
行锁(record lock):
间隙锁(Gap Lock):
如索引中存在三个聚簇节点Id[1,3,6],事务A执行update table t1 set name = 'ss' where t1.id = 3,若没有间隙锁,事务可以同时执行insert into table(id, name) values(4, 's4');但由于间隙锁的存在(1,6),事务B需要等待事务A释放间隙锁之后才能新增成功。在当前读时,索引扫描到的记录都会加上间隙锁,区间为前开后开。
临键锁(next-key lock):
InnoDB Buffer
InnoDB中查询记录是一条一条的,但是读取时是以数据页为单位的,读取一条记录时会将记录所在的数据页整个读取到缓冲池中。
Change Buffer的应用
-
如果对应数据页(聚簇和二级)已经存在于内存:直接更新内存中的数据页,记录redo-log、binlog; -
如果数据页不在内存之中,对于唯一索引(包括聚簇),需要将数据加载到内存中进行唯一性约束校验,校验通过再在内存中更新数据、记录redolog;对于非唯一索引,直接将数据更改日志存储在change-buffer中(不写磁盘),记录redolog、binlog。



-
 骨干教师培养计划 悔过书 可盐可甜可奶可仙的网名 绿的诗句 怀念青春的经典句子 女生网名好听优雅 睡前小故事哄女朋友 写一种你喜欢的食物 中国的别称有哪些 自然景观作文 四年级写一小段新闻 带风的网名 我要的是葫芦教学反思 会议室管理制度 师德师风学习体会 好听又沙雕的吃鸡名字 大学生消费情况调查报告 圣诞节介绍 欢迎词 市场总监职责 外出学习心得体会 机械类专业就业方向及前景 美国人常用名字 教育案例范文 洪涝灾害的原因 富有诗意的网名 情侣文案 这次我选择了坚强 小众网名 祝自己生日快乐的句子(0) 回复 (0)
骨干教师培养计划 悔过书 可盐可甜可奶可仙的网名 绿的诗句 怀念青春的经典句子 女生网名好听优雅 睡前小故事哄女朋友 写一种你喜欢的食物 中国的别称有哪些 自然景观作文 四年级写一小段新闻 带风的网名 我要的是葫芦教学反思 会议室管理制度 师德师风学习体会 好听又沙雕的吃鸡名字 大学生消费情况调查报告 圣诞节介绍 欢迎词 市场总监职责 外出学习心得体会 机械类专业就业方向及前景 美国人常用名字 教育案例范文 洪涝灾害的原因 富有诗意的网名 情侣文案 这次我选择了坚强 小众网名 祝自己生日快乐的句子(0) 回复 (0) -
讨债公司/蓝月传奇辅助/蓝月辅助(0) 回复 (0)


